Табличные выражения. Сложные запросы к базе данных MySQL. Простые UPDATE запросы к базе данных MySQL
Табличными выражениями называются подзапросы, которые используются там, где ожидается наличие таблицы. Существует два типа табличных выражений:
производные таблицы;
обобщенные табличные выражения.
Эти две формы табличных выражений рассматриваются в следующих подразделах.
Производные таблицы
Производная таблица (derived table) - это табличное выражение, входящее в предложение FROM запроса. Производные таблицы можно применять в тех случаях, когда использование псевдонимов столбцов не представляется возможным, поскольку транслятор SQL обрабатывает другое предложение до того, как псевдоним станет известным. В примере ниже показана попытка использовать псевдоним столбца в ситуации, когда другое предложение обрабатывается до того, как станет известным псевдоним:
USE SampleDb; SELECT MONTH(EnterDate) as enter_month FROM Works_on GROUP BY enter_month;
Попытка выполнить этот запрос выдаст следующее сообщение об ошибке:
Msg 207, Level 16, State 1, Line 5 Invalid column name "enter_month". (Сообщение 207: уровень 16, состояние 1, строка 5 Недопустимое имя столбца enter_month)
Причиной ошибки является то обстоятельство, что предложение GROUP BY обрабатывается до обработки соответствующего списка инструкции SELECT, и при обработке этой группы псевдоним столбца enter_month неизвестен.
Эту проблему можно решить, используя производную таблицу, содержащую предшествующий запрос (без предложения GROUP BY), поскольку предложение FROM исполняется перед предложением GROUP BY:
USE SampleDb; SELECT enter_month FROM (SELECT MONTH(EnterDate) as enter_month FROM Works_on) AS m GROUP BY enter_month;
Результат выполнения этого запроса будет таким:
Обычно табличное выражение можно разместить в любом месте инструкции SELECT, где может появиться имя таблицы. (Результатом табличного выражения всегда является таблица или, в особых случаях, выражение.) В примере ниже показывается использование табличного выражения в списке выбора инструкции SELECT:
Результат выполнения этого запроса:

Обобщенные табличные выражения
Обобщенным табличным выражением (OTB) (Common Table Expression - сокращенно CTE) называется именованное табличное выражение, поддерживаемое языком Transact-SQL. Обобщенные табличные выражения используются в следующих двух типах запросов:
нерекурсивных;
рекурсивных.
Эти два типа запросов рассматриваются в следующих далее разделах.
OTB и нерекурсивные запросы
Нерекурсивную форму OTB можно использовать в качестве альтернативы производным таблицам и представлениям. Обычно OTB определяется посредством предложения WITH и дополнительного запроса, который ссылается на имя, используемое в предложении WITH. В языке Transact-SQL значение ключевого слова WITH неоднозначно. Чтобы избежать неопределенности, инструкцию, предшествующую оператору WITH, следует завершать точкой с запятой.
USE AdventureWorks2012; SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") AND Freight > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005")/2.5;
Запрос в этом примере выбирает заказы, чьи общие суммы налогов (TotalDue) большие, чем среднее значение по всем налогам, и плата за перевозку (Freight) которых больше чем 40% среднего значения налогов. Основным свойством этого запроса является его объемистость, поскольку вложенный запрос требуется писать дважды. Одним из возможных способов уменьшить объем конструкции запроса будет создать представление, содержащее вложенный запрос. Но это решение несколько сложно, поскольку требует создания представления, а потом его удаления после окончания выполнения запроса. Лучшим подходом будет создать OTB. В примере ниже показывается использование нерекурсивного OTB, которое сокращает определение запроса, приведенного выше:
USE AdventureWorks2012; WITH price_calc(year_2005) AS (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT year_2005 FROM price_calc) AND Freight > (SELECT year_2005 FROM price_calc)/2.5;
Синтаксис предложения WITH в нерекурсивных запросах имеет следующий вид:
Параметр cte_name представляет имя OTB, которое определяет результирующую таблицу, а параметр column_list - список столбцов табличного выражения. (В примере выше OTB называется price_calc и имеет один столбец - year_2005.) Параметр inner_query представляет инструкцию SELECT, которая определяет результирующий набор соответствующего табличного выражения. После этого определенное табличное выражение можно использовать во внешнем запросе outer_query. (Внешний запрос в примере выше использует OTB price_calc и ее столбец year_2005, чтобы упростить употребляющийся дважды вложенный запрос.)
OTB и рекурсивные запросы
В этом разделе представляется материал повышенной сложности. Поэтому при первом его чтении рекомендуется его пропустить и вернуться к нему позже. Посредством OTB можно реализовывать рекурсии, поскольку OTB могут содержать ссылки на самих себя. Основной синтаксис OTB для рекурсивного запроса выглядит таким образом:
Параметры cte_name и column_list имеют такое же значение, как и в OTB для нерекурсивных запросов. Тело предложения WITH состоит из двух запросов, объединенных оператором UNION ALL . Первый запрос вызывается только один раз, и он начинает накапливать результат рекурсии. Первый операнд оператора UNION ALL не ссылается на OTB. Этот запрос называется опорным запросом или источником.
Второй запрос содержит ссылку на OTB и представляет ее рекурсивную часть. Вследствие этого он называется рекурсивным членом. В первом вызове рекурсивной части ссылка на OTB представляет результат опорного запроса. Рекурсивный член использует результат первого вызова запроса. После этого система снова вызывает рекурсивную часть. Вызов рекурсивного члена прекращается, когда предыдущий его вызов возвращает пустой результирующий набор.
Оператор UNION ALL соединяет накопившиеся на данный момент строки, а также дополнительные строки, добавленные текущим вызовом рекурсивного члена. (Наличие оператора UNION ALL означает, что повторяющиеся строки не будут удалены из результата.)
Наконец, параметр outer_query определяет внешний запрос, который использует OTB для получения всех вызовов объединения обеих членов.
Для демонстрации рекурсивной формы OTB мы используем таблицу Airplane, определенную и заполненную кодом, показанным в примере ниже:
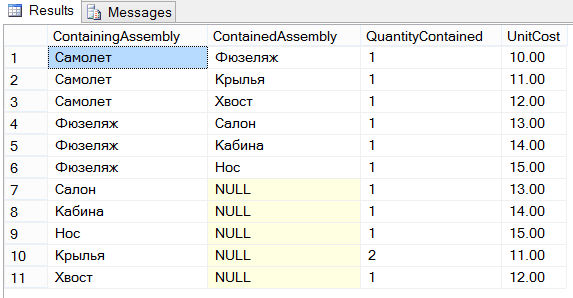
USE SampleDb; CREATE TABLE Airplane (ContainingAssembly VARCHAR(10), ContainedAssembly VARCHAR(10), QuantityContained INT, UnitCost DECIMAL (6,2)); INSERT INTO Airplane VALUES ("Самолет", "Фюзеляж",1, 10); INSERT INTO Airplane VALUES ("Самолет", "Крылья", 1, 11); INSERT INTO Airplane VALUES ("Самолет", "Хвост",1, 12); INSERT INTO Airplane VALUES ("Фюзеляж", "Салон", 1, 13); INSERT INTO Airplane VALUES ("Фюзеляж", "Кабина", 1, 14); INSERT INTO Airplane VALUES ("Фюзеляж", "Нос",1, 15); INSERT INTO Airplane VALUES ("Салон", NULL, 1,13); INSERT INTO Airplane VALUES ("Кабина", NULL, 1, 14); INSERT INTO Airplane VALUES ("Нос", NULL, 1, 15); INSERT INTO Airplane VALUES ("Крылья", NULL,2, 11); INSERT INTO Airplane VALUES ("Хвост", NULL, 1, 12);
Таблица Airplane состоит из четырех столбцов. Столбец ContainingAssembly определяет сборку, а столбец ContainedAssembly - части (одна за другой), которые составляют соответствующую сборку. На рисунке ниже приведена графическая иллюстрация возможного вида самолета и его составляющих частей:

Таблица Airplane состоит из следующих 11 строк:
В примере ниже показано применение предложения WITH для определения запроса, который вычисляет общую стоимость каждой сборки:
USE SampleDb; WITH list_of_parts(assembly1, quantity, cost) AS (SELECT ContainingAssembly, QuantityContained, UnitCost FROM Airplane WHERE ContainedAssembly IS NULL UNION ALL SELECT a.ContainingAssembly, a.QuantityContained, CAST(l.quantity * l.cost AS DECIMAL(6,2)) FROM list_of_parts l, Airplane a WHERE l.assembly1 = a.ContainedAssembly) SELECT assembly1 "Деталь", quantity "Кол-во", cost "Цена" FROM list_of_parts;
Предложение WITH определяет список OTB с именем list_of_parts, состоящий из трех столбцов: assembly1, quantity и cost. Первая инструкция SELECT в примере вызывается только один раз, чтобы сохранить результаты первого шага процесса рекурсии. Инструкция SELECT в последней строке примера отображает следующий результат.
Для извлечения данных из базы данных используется язык SQL. SQL - это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
Что такое SQL?
SQL - это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI .
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис - это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = "Mary";
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных .
Инструкции SELECT
Инструкция SELECT служит для описания набора данных на языке SQL. Она содержит полное описание набора данных, которые необходимо получить из базы данных, включая следующее:
таблицы, в которых содержатся данные;
связи между данными из разных источников;
поля или вычисления, на основе которых отбираются данные;
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
|
Предложение SQL |
Описание |
Обязательное |
|
Определяет поля, которые содержат нужные данные. |
||
|
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
||
|
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
||
|
Определяет порядок сортировки результатов. |
||
|
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
|
|
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
|
Термин SQL |
Сопоставимая часть речи |
Определение |
Пример |
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
Ключевое слово, которое представляет действие или изменяет его. |
|
|
константа |
существительное |
Значение, которое не изменяется, например число или NULL. |
|
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
1. Предложение SELECT
2. Предложение FROM
3. Предложение WHERE
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT , Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора ("[Адрес электронной почты]" и "Компания").
Если идентификатор содержит пробелы или специальные знаки (например, "Адрес электронной почты"), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City="Seattle"
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город="Ростов").
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю "Компания" в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля "Компания", - отсортировать их по полю "Адрес электронной почты" в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC,
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY .
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL .
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY .
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT(), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT()>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, - в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING .
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются "Товары" и "Услуги". Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах "Продукты" и "Услуги" предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье
Каждый из нас регулярно сталкивается и пользуется различными базами данных. Когда мы выбираем адрес электронной почты, мы работаем с базой данных. Базы данных используют поисковые сервисы, банки для хранения данных о клиентах и т.д.
Но, несмотря на постоянное использование баз данных, даже для многих разработчиков программных систем остается много «белых пятен» из-за разного толкования одних и тех же терминов. Мы дадим краткое определение основных терминов баз данных перед рассмотрением языка SQL. Итак.
База данных - файл или набор файлов для хранения упорядоченных структур данных и их взаимосвязей. Очень часто базой данных называют систему управления - это только хранилище информации в определенном формате и может работать с различными СУБД.
Таблица - представим себе папку, в которой хранятся документы, сгруппированные по определенному признаку, например список заказов за последний месяц. Это и есть таблица в компьютерной Отдельная таблица имеет свое уникальное имя.
Тип данных - вид информации, разрешенной для хранения в отдельном столбце или строке. Это могут быть числа или текст определенного формата.
Столбец и строка - все мы работали с электронными таблицами, в которых также присутствуют строки и столбцы. Любая реляционная база данных работает с таблицами аналогичным образом. Строки иногда называют записями.
Первичный ключ - каждая строка таблицы может иметь один или несколько столбцов для ее уникальной идентификации. Без первичного ключа очень трудно производить обновление, изменение и удаление нужных строк.
Что такое SQL?
SQL (англ. - язык структурированных запросов) был разработан только для работы с базами данных и в настоящий момент является стандартом для всех популярных СУБД. Синтаксис языка состоит из небольшого количества операторов и прост в изучении. Но, несмотря на внешнюю простоту, он позволяет создание sql запросов для сложных операций с БД любого размера.
С 1992 г. существует общепринятый стандарт, называемый ANSI SQL. Он определяет базовый синтаксис и функции операторов и поддерживается всеми лидерами рынка СУБД, такими как ORACLE Рассмотреть все возможности языка в одной небольшой статье невозможно, поэтому мы кратко рассмотрим только основные SQL запросы. Примеры наглядно показывают простоту и возможности языка:
- создание баз и таблиц;
- выборка данных;
- добавление записей;
- модификация и удаление информации.
Типы данных SQL
Все столбцы в таблице базы данных хранят один тип данных. Типы данных в SQL такие же, как и в других языках программирования.
Создаем таблицы и базы данных

Создавать новые базы, таблицы и другие запросы в SQL можно двумя способами:
- Операторами SQL через консоль СУБД
- Используя интерактивные средства администрирования, входящие в состав сервера баз данных.
Создается новая база данных оператором CREATE DATABASE <наименование базы данных>; . Как видим, синтаксис прост и лаконичен.
Таблицы внутри базы данных создаем оператором CREATE TABLE со следующими параметрами:
- наименование таблицы
- имена и типы данных столбцов
В качестве примера создадим таблицу Commodity со следующими столбцами:
Создаем таблицу:
CREATE TABLE Commodity
(commodity_id CHAR(15) NOT NULL,
vendor_id CHAR(15) NOT NULL,
commodity_name CHAR(254) NULL,
commodity_price DECIMAL(8,2) NULL,
commodity_desc VARCHAR(1000) NULL);
Таблица состоит из пяти столбцов. После наименования идет тип данных, столбцы разделяются запятыми. Значение столбца может принимать пустые значения (NULL) или должно быть обязательно заполнено (NOT NULL), и это определяется при создании таблицы.
Выборка данных из таблицы

Оператор выборки данных - самые часто используемые SQL запросы. Для получения информации необходимо указать, что мы хотим выбрать из такой таблицы. Вначале простой пример:
SELECT commodity_name FROM Commodity
После оператора SELECT указываем имя столбца для получения информации, а FROM определяет таблицу.
Результатом выполнения запроса будут все строки таблицы со значениями Commodity_name в том порядке, в котором они были внесены в базу данных т.е. без всякой сортировки. Для упорядочивания результата используется дополнительный оператор ORDER BY.
Для запроса по нескольким полям перечисляем их через запятую, как в следующем примере:
SELECT commodity_id, commodity_name, commodity_price FROM Commodity
Есть возможность получить как результат запроса значение всех столбцов строки. Для этого используется знак «*»:
SELECT * FROM Commodity
- Дополнительно SELECT поддерживает:
- Сортировку данных (оператор ORDER BY)
- Выбор согласно условиям (WHERE)
- Группировку срок (GROUP BY)
Добавляем строку

Для добавления строки в таблицу используются SQL запросы с оператором INSERT. Добавление может производиться тремя способами:
- добавляем новую целую строку;
- часть строки;
- результаты запроса.
Для добавления полной строки необходимо указать имя таблицы и значения столбцов (полей) новой строки. Приведем пример:
INSERT INTO Commodity VALUES("106 ", "50", "Coca-Cola", "1.68", "No Alcogol ,)
Пример добавляет в таблицу новый товар. Значения указываются после VALUES для каждого столбца. Если нет соответствующего значения для столбца, то необходимо указывать NULL. Столбцы заполняются значениями в порядке, указанном при создании таблицы.
В случае добавления только части строки необходимо явно указать наименования столбцов, как в примере:
INSERT INTO Commodity (commodity_id, vendor_id, commodity_name)
VALUES("106 ", ‘50", "Coca-Cola",)
Мы ввели только идентификаторы товара, поставщика и его наименование, а остальные поля отставили пустыми.
Добавление результатов запроса
В основном INSERT используется для добавления строк, но может использоваться и для добавления результатов оператора SELECT.
Изменение данных

Для изменения информации в полях таблицы базы данных необходимо использовать оператор UPDATE. Оператор может применяться двумя способами:
- Обновляются все строки в таблице.
- Только для определенной строки.
UPDATE состоит из трех основных элементов:
- таблица, в которой необходимо производить изменения;
- имена полей и их новые значения;
- условия выбора строк для изменения.
Рассмотрим пример. Допустим, у товара с ID=106 изменилась стоимость, поэтому эту строку необходимо обновить. Пишем следующий оператор:
UPDATE Commodity SET commodity_price = "3.2" WHERE commodity_id = "106"
Мы указали имя таблицы, в нашем случае Commodity, где будет производиться обновление, затем после SET - новое значение столбца и нашли нужную запись, указав в WHERE нужное значение ID.
Для изменения нескольких столбцов после оператора SET указываются несколько пар столбец-значение, разделенных запятыми. Смотрим пример, в котором обновляется наименование и цена товара:
UPDATE Commodity SET commodity_name=’Fanta’, commodity_price = "3.2" WHERE commodity_id = "106"
Для удаления информации в столбце можно присвоить ему значение NULL, если это позволяет структура таблицы. Необходимо помнить, что NULL - это именно «никакое» значение, а не нуль в виде текста или числа. Удалим описание товара:
UPDATE Commodity SET commodity_desc = NULL WHERE commodity_id = "106"
Удаление строк

SQL запросы на удаление строк в таблице выполняются оператором DELETE. Есть два варианта использования:
- в таблице удаляются определенные строки;
- удаляются все строки в таблице.
Пример удаления одной строки из таблицы:
DELETE FROM Commodity WHERE commodity_id = "106"
После DELETE FROM указываем имя таблицы, в которой будут удаляться строки. Оператор WHERE содержит условие, по которому будут выбираться строки для удаления. В примере мы удаляем строку товара с ID=106. Указывать WHERE очень важно т.к. пропуск этого оператора приведт к удалению всех строк в таблице. Это относится и к изменению значения полей.
В операторе DELETE не указываются наименования столбцов и метасимволы. Он полностью удаляет строки, а удалить отдельный столбец он не может.
Использование SQL в Microsoft Access

Обычно используется в интерактивном режиме для создания таблиц, баз данных, для управления, изменения, анализа данных в базе данных и с целью внедрить запросы SQL Access через удобный интерактивный конструктор запросов (Query Designer), используя который можно построить и немедленно выполнить операторов SQL любой сложности.
Также поддерживается режим доступа к серверу, при котором СУБД Access может использоваться как генератор SQL-запросов к любому ODBC источнику данных. Эта возможность позволяет приложениям Access взаимодействовать с любого формата.
Расширения SQL
Поскольку SQL запросы не имеют всех возможностей процедурных языков программирования, таких как циклы, ветвления и т.д., производители СУБД разрабатывают свой вариант SQL с расширенными возможностями. В первую очередь это поддержка хранимых процедур и стандартных операторов процедурных языков.
Наиболее распространенные диалекты языка:
- Oracle Database - PL/SQL
- Interbase, Firebird - PSQL
- Microsoft SQL Server - Transact-SQL
- PostgreSQL - PL/pgSQL.
SQL в Интернет
СУБД MySQL распространяется под свободной лицензией GNU General Public License. Имеется коммерческая лицензия с возможностью разработки заказных модулей. Как составная часть входит в наиболее популярные сборки Интернет-серверов, таких как XAMPP, WAMP и LAMP, и является самой популярной СУБД для разработки приложений в сети Интернет.
Была разработана компанией Sun Microsystems и в настоящий момент поддерживается корпорацией Oracle. Поддерживаются базы данных размером до 64 терабайт, стандарт синтаксиса SQL:2003, репликация баз данных и облачных сервисов.
Синтаксис:
* где fields1
— поля для выборки через запятую, также можно указать все поля знаком *; table
— имя таблицы, из которой вытаскиваем данные; conditions
— условия выборки; fields2
— поле или поля через запятую, по которым выполнить сортировку; count
— количество строк для выгрузки.
* запрос в квадратных скобках не является обязательным для выборки данных.
Простые примеры использования select
1. Обычная выборка данных:
> SELECT * FROM users
2. Выборка данных с объединением двух таблиц (JOIN):
SELECT u.name, r.* FROM users u JOIN users_rights r ON r.user_id=u.id
* в данном примере идет выборка данных с объединением таблиц users и users_rights . Объединяются они по полям user_id (в таблице users_rights) и id (users). Извлекается поле name из первой таблицы и все поля из второй.
3. Выборка с интервалом по времени и/или дате
а) известна точка начала и определенный временной интервал:
* будут выбраны данные за последний час (поле date ).
б) известны дата начала и дата окончания:
25.10.2017 и 25.11.2017 .
в) известны даты начала и окончания + время:
* выбираем данные в промежутке между 25.03.2018 0 часов 15 минут и 25.04.2018 15 часов 33 минуты и 9 секунд .
г) вытаскиваем данные за определенные месяц и год:
* извлечем данные, где в поле date присутствуют значения для апреля 2018 года.
4. Выборка максимального, минимального и среднего значения:
> SELECT max(area), min(area), avg(area) FROM country
* max — максимальное значение; min — минимальное; avg — среднее.
5. Использование длины строки:
* данный запрос должен показать всех пользователей, имя которых состоит из 5 символов.
Примеры более сложных запросов или используемых редко
1. Объединение с группировкой выбранных данных в одну строку (GROUP_CONCAT):
* из таблицы users извлекаются данные по полю id , все они помещаются в одну строку, значения разделяются запятыми .
2. Группировка данных по двум и более полям:
> SELECT * FROM users GROUP BY CONCAT(title, "::", birth)
* итого, в данном примере мы сделаем выгрузку данных из таблицы users и сгруппируем их по полям title и birth . Перед группировкой мы делаем объединение полей в одну строку с разделителем :: .
3. Объединение результатов из двух таблиц (UNION):
> (SELECT id, fio, address, "Пользователи" as type FROM users)
UNION
(SELECT id, fio, address, "Покупатели" as type FROM customers)
* в данном примере идет выборка данных из таблиц users и customers .
4. Выборка средних значений, сгруппированных за каждый час:
SELECT avg(temperature), DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H") as hour_datetime FROM archive GROUP BY DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H")
* здесь мы извлекаем среднее значение поля temperature из таблицы archive и группируем по полю datetimeupdate (с разделением времени за каждый час).
Вставка (INSERT)
Синтаксис 1:
> INSERT INTO
| AVG(X) | Возвращает среднее значение всех не NULL X в группе. Строковые и BLOB-значения, не похожие на числа, рассматриваются как 0. Результатом AVG() всегда является значение с плавающей запятой, даже если все входные значения — целые числа. |
| Первая форма возвращает число раз, которое X не является NULL в группе. Вторая форма (с аргументом *) возвращает общее число строк в группе. | |
| MAX(X) | Возвращает максимальное значение всех значений в группе. Для определения максимального значения используется обычный порядок сортировки. |
| MIN(X) | Возвращает минимальное не NULL значение всех значений в группе. Для определения минимального значения используется обычный порядок сортировки. Если все значения в группе равны NULL , возвращается NULL . |
| Возвращает сумму чисел всех не NULL значений в группе. Если все значения равны NULL , то SUM() возвращает NULL , а TOTAL() возвращает 0.0 . Результатом TOTAL() всегда является значение с плавающей запятой. Результатом SUM() является целочисленное значение, если все не NULL входные значения являются целыми числами. Если какое-либо входное значение для SUM() не является целым числом и не NULL , SUM() возвращает значение с плавающей запятой. Это значение может быть приблизительным числом верной суммы. |
В любой из предыдущих статических функций, принимающих отдельный аргумент, перед этим аргументом можно использовать ключевое слово DISTINCT . В таком случае повторяющиеся элементы фильтруются перед передачей в статическую функцию. Например, вызов функции COUNT(DISTINCT x) возвращает число неодинаковых значений столбца X, а не общее число не NULL значений в столбце x .
Скалярные функции
Скалярные функции выполняют операции со значениями по одной строке за раз. Ниже приводится список этих функций:
| ABS(X) | Возвращает абсолютное значение аргумента X . |
| COALESCE(X, Y, ...) | Возвращает копию первого не NULL аргумента. Если все аргументы равны NULL , возвращается NULL . Требуется, по меньшей мере, два аргумента. |
| GLOB(X, Y) | Эта функция служит для реализации синтаксиса X GLOB Y . |
| IFNULL(X, Y) | Возвращает копию первого не NULL аргумента. Если оба аргумента равны NULL , возвращается NULL . Эта функция действует так же, как COALESCE() . |
| HEX(X) | Аргумент рассматривается как значение типа хранения BLOB. Результатом является шестнадцатиричное отображение содержимого этого значения. |
| LAST_INSERT_ROWID() | Возвращает идентификатор (созданный первичный ключ) последней строки, вставленной в базу данных через текущий экземпляр SQLConnection. Это значение совпадает со значением, которое возвращает свойство SQLConnection.lastInsertRowID . |
| LENGTH(X) | Возвращает длину строки X в символах. |
| LIKE(X, Y [, Z]) | Эта функция служит для реализации синтаксиса SQL X LIKE Y . Если присутствует необязательное предложение ESCAPE , функция вызывается с тремя аргументами. В противном случае она вызывается только с двумя аргументами. |
| LOWER(X) | Возвращает копию строки X с преобразованием всех символов в строчные. |
| Возвращает строку с удаленными пробелами слева от X . Если указан аргумент Y , функция удаляет любые символы в Y слева от X . | |
| MAX(X, Y, ...) | Возвращает аргумент с максимальным значением. Аргументы могут представлять строки, добавленные к числам. Максимальное значение определяется заданным порядком сортировки. Следует отметить, что функция MAX() является простой, когда имеет 2 или более аргументов, но с одним аргументом является статической функцией. |
| MIN(X, Y, ...) | Возвращает аргумент с минимальным значением. Аргументы могут представлять строки, добавленные к числам. Минимальное значение определяется заданным порядком сортировки. Следует отметить, что функция MIN() является простой, когда имеет 2 или более аргументов, но с одним аргументом является статической функцией. |
| NULLIF(X, Y) | Возвращает первый аргумент, если аргументы отличаются; в противном случае возвращает NULL . |
| QUOTE(X) | Эта подпрограмма возвращает строку, которая представляет значение своего аргумента, подходящее для вставки в другую инструкцию SQL. Строки заключаются в одинарные кавычки с escape-символами во внутренних кавычках в зависимости от необходимости. Классы хранения BLOB кодируются в шестнадцатиричные литералы. Эту функция полезна при написании триггеров для реализации функций отмены или повтора действий. |
| RANDOM(*) | Возвращает псевдослучайное целое число из интервала -9223372036854775808 — 9223372036854775807. Это случайное значение не является стойким к шифрованию. |
| RANDOMBLOB(N) | Возвращает N -байтов объекта BLOB с псевдослучайными байтами. N должно быть положительным целым числом. Это случайное значение не является стойким к шифрованию. Если значение N является отрицательным, возвращается один байт. |
| Округляет число X до Y знаков справа от десятичной точки. Если аргумент Y опущен, используется 0. | |
| Возвращает строку с удаленными пробелами слева от X . Если указан аргумент Y , функция удаляет любые символы в Y справа от X . | |
| SUBSTR(X, Y, Z) | Возвращает подстроку входящей строки X , начинающейся с Y символа длиной Z символов. Крайний левый символ X представляет положение индекса 1. Если Y является отрицательным, первый символ подстроки находится путем подсчета справа, а не слева. |
| Возвращает строку с удаленными пробелами слева и справа от X . Если указан аргумент Y , функция удаляет любые символы в Y слева и справа от X . | |
| TYPEOF(X) | Возвращает тип выражения X . Возможные возвращаемые значения: "null", "integer", "real", "text" и "blob". Дополнительные сведения о типах данных см. в разделе . |
| UPPER(X) | Возвращает копию входящей строки X с преобразованием всех символов в прописные. |
| ZEROBLOB(N) | Возвращает BLOB с N байтами 0x00. |
Функции форматирования даты и времени
Функции форматирования даты и времени представляют собой группу скалярных функций, используемых для создания форматированных данных даты и времени. Следует отметить, что эти функции работают со строковыми и числовыми значениями и возвращают их. Эти функции не предназначены для использования с типом данных DATE. Если их использовать с данными в столбце, объявленный тип данных которого — DATE, их поведение будет не таким, как требуется.
| DATE(T, ...) | Функция DATE() возвращает строку, содержащую дату в следующем формате: ГГГГ-ММ-ДД. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| TIME(T, ...) | Функция TIME() возвращает строку, содержащую время в формате ЧЧ:ММ:СС. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| DATETIME(T, ...) | Функция DATETIME() возвращает строку, содержащую дату и время в формате ГГГГ-ММ-ДД ЧЧ:ММ:СС. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| JULIANDAY(T, ...) | Функция JULIANDAY() возвращает число, обозначающее количество дней с полудня по Гринвичу 24 ноября 4714 до нашей эры и заданную дату. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| STRFTIME(F, T, ...) | Подпрограмма STRFTIME() возвращает дату по заданной строке формата в качестве первого аргумента F . Строка формата поддерживает следующие подстановочные знаки: Второй параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
Форматы времени
Формат строки времени может быть любым из следующих:
| ГГГГ-ММ-ДД | 2007-06-15 |
| ГГГГ-ММ-ДД ЧЧ:ММ | 2007-06-15 07:30 |
| ГГГГ-ММ-ДД ЧЧ:ММ:СС | 2007-06-15 07:30:59 |
| ГГГГ-ММ-ДД ЧЧ:ММ:СС,ССС | 2007-06-15 07:30:59.152 |
| ГГГГ-ММ-ДДTЧЧ:ММ | 2007-06-15T07:30 |
| ГГГГ-ММ-ДДTЧЧ:ММ:СС | 2007-06-15T07:30:59 |
| ГГГГ-ММ-ДДTЧЧ:ММ:СС,ССС | 2007-06-15T07:30:59.152 |
| ЧЧ:ММ | 07:30 (дата: 2000-01-01) |
| ЧЧ:ММ:СС | 07:30:59 (дата: 2000-01-01) |
| ЧЧ:ММ:СС,ССС | 07:30:59:152 (дата: 2000-01-01) |
| now | Текущая дата и время в формате UTC. |
| ДДДД.ДДДД | День по юлианскому календарю в виде числа с плавающей запятой |
Символ T в этих форматах представляет буквенный символ "T", разделяющий дату и время. Форматы, включающие только время, предполагают дату 2001-01-01.
Модификаторы
После строки времени может следовать ноль или несколько модификаторов, изменяющих дату или толкование даты. Доступны следующие модификаторы:
| NNN дней | Число дней, прибавляемое к времени. |
| NNN часов | Число часов, прибавляемое к времени. |
| NNN минут | Число минут, прибавляемое к времени. |
| NNN,NNNN секунд | Число секунд или миллисекунд, прибавляемое к времени. |
| NNN месяцев | Число месяцев, прибавляемое к времени. |
| NNN лет | Число лет, прибавляемое к времени. |
| начало месяца | Смещение времени назад к началу месяца. |
| начало года | Смещение времени назад к началу года. |
| начало дня | Смещение времени назад к началу дня. |
| день недели N | Смещение времени вперед на указанный день недели. (0 = воскресенье, 1 = понедельник и т.д.) |
| localtime | Преобразование даты в местное время |
| utc | Преобразование даты в формат UTC |
Операторы
SQL поддерживает большое число операторов, включая распространенные операторы, существующие в большинстве языков программирования, а также несколько уникальных для SQL операторов.
Общие операторы
Следующие двоичные операторы допускаются в блоке SQL и перечислены в порядке приоритета — от высшего до низшего:
|| * / % + - << >> & | < <= > >= = == != <> IN AND ORПоддерживаются унарные префиксные операторы:
- ! ~ NOT
Оператор COLLATE можно представить как унарный постфиксный оператор. Оператор COLLATE имеет наивысший приоритет. Он всегда имеет более тесную привязку, чем префиксный унарный оператор или любой двоичный оператор.
Следует отметить, что существует две разновидности операторов равенства и неравенства. Равенство может иметь форму = или == . Оператор неравенства может иметь вид!= или <> .
Оператор || является строковым оператором сцепления — он соединяет две строки своих операндов.
Оператор % выдает остаток от деления правого операнда на левый операнд.
Результатом любого двоичного оператора является числовое значение, но это не относится к оператору сцепления || , который выдает строковый результат.
Операторы SQL
LIKE
Оператор LIKE выполняет сравнение шаблонов.
Expr::= (column-name | expr) LIKE pattern pattern::= "[ string | % | _ ]"
Операнд справа от оператора LIKE содержит шаблон, а левые операнд содержит строку для соответствия шаблону. Символ процента (%) в шаблоне представляет собой подстановочный знак и соответствует любой последовательности символов в строке (или отсутствию символов). Символ подчеркивания (_) в шаблоне соответствует любому отдельному символу в строке. Любой другой символ соответствует самому себе или эквивалентному символу нижнего/верхнего регистра, то есть совпадения определяются вне зависимости от регистра. (Примечание. Ядро СУБД понимает только верхний/нижний регистр 7-битных символов латиницы. Следовательно, оператор LIKE учитывает регистра для 8-битных символов iso8859 или символов UTF-8. Например, выражение "a" LIKE "A" является TRUE , но "æ" LIKE "Æ" — FALSE). Зависимость символов латинского алфавита от регистра можно изменить при помощи свойства SQLConnection.caseSensitiveLike .
Если присутствует необязательное предложение ESCAPE , то выражение после ключевого слова ESCAPE должно приводить к строке, состоящей из одного символа. Этот символ можно использовать в шаблоне LIKE для соответствия литеральному проценту или символам подчеркивания. Escape-знак после символа процента, символ подчеркивания или сам по себе соответствует символу литерального процента, символу подчеркивания или escape-знаку в строке, соответственно.
GLOB
Оператор GLOB похож на LIKE , но использует синтаксис глобализации Unix-файла для своих подстановочных знаков. В отличие от LIKE , GLOB зависит от регистра.
IN
Оператор IN вычисляет, равен ли его левый операнд одному из значений правого операнда (набору значений в скобках).
In-expr::= expr IN (value-list) | expr IN (select-statement) | expr IN table-name value-list::= literal-value [, literal-value]*
Правый операнд может быть набором литеральных значений, разделенных запятыми, или результатом инструкции SELECT . Описание и ограничения при использовании инструкций SELECT при использовании в качестве правого операнда оператора IN см. в описании инструкций SELECT .
BETWEEN...AND
Оператор BETWEEN...AND эквивалентен использованию двух выражений с операторами >= и <= . Например, выражение x BETWEEN y AND z эквивалентно x >= y AND x <= z .
NOT
Оператор NOT является оператором отрицания. Перед операторами GLOB , LIKE и IN можно поставить ключевое слово NOT для обращения значения теста (другими словами, для проверки того, что значение не соответствует указанному шаблону).
Параметры
Параметр указывает местозаполнитель в выражении для литерального значения, который заполняется во время выполнения путем присвоения значения ассоциативному массиву SQLStatement.parameters . Параметры могут иметь три формы:
Неподдерживаемые возможности SQL
- Ограничения FOREIGN KEY . Разбор ограничений FOREIGN KEY выполняется, но они не применяются.
- Триггеры . Триггеры FOR EACH STATEMENT не поддерживаются (все триггеры должны быть FOR EACH ROW). Триггеры INSTEAD OF не поддерживаются для таблиц (для представлений допускаются только триггеры INSTEAD OF). Рекурсивные триггеры (вызывающие самих себя) не поддерживаются.
- ALTER TABLE . Поддерживаются только варианты RENAME TABLE и ADD COLUMN команды ALTER TABLE . Другие типы операций ALTER TABLE , такие как DROP COLUMN , ALTER COLUMN , ADD CONSTRAINT и т.д., пропускаются.
- Вложенные транзакции . Допускается только одна активная транзакция.
- RIGHT и FULL OUTER JOIN . RIGHT OUTER JOIN или FULL OUTER JOIN не поддерживаются.
- Обновление VIEW . Представление доступно только для чтения. Для представления невозможно выполнить инструкцию DELETE , INSERT или UPDATE . Триггер INSTEAD OF , запускаемый при попытке выполнения DELETE , INSERT или UPDATE для представления, поддерживается и может использоваться для обновления вспомогательных таблиц в теле триггера.
- GRANT и REVOKE . База данных представляет собой простой файл на диске; единственные применяемые разрешения доступа — это обычные разрешения доступа к файлам в базовой операционной системе. Команды GRANT и REVOKE , обычно существующие в клиентских/серверных реляционных СУБД, не реализованы.
Следующие элементы SQL и возможности SQLite поддерживаются в некоторых реализациях SQLite, но не поддерживаются в Adobe AIR. Большая часть этих возможностей доступна через методы класса SQLConnection.
- Связанные с транзакциями элементы SQL (BEGIN , END , COMMIT , ROLLBACK) : Следующие функции доступны через связанными с транзакциями методы класса SQLConnection : SQLConnection.begin() , SQLConnection.commit() и SQLConnection.rollback() .
- ANALYZE SQLConnection.analyze() .
- ATTACH : Эта возможность доступна через метод SQLConnection.attach() .
- COPY
- CREATE VIRTUAL TABLE : Эта инструкция не поддерживается.
- DETACH : Эта возможность доступна через метод SQLConnection.detach() .
- PRAGMA : Эта инструкция не поддерживается.
- VACUUM : Эта возможность доступна через метод SQLConnection.compact() .
- Доступ к системной таблице отсутствует . Системные таблицы, в том числе sqlite_master и другие таблицы с префиксом "sqlite_" не доступны в инструкциях SQL. Среда времени выполнения включает API схемы, который представляет объектно-ориентированный способ доступа к данным схемы. Дополнительные сведения см. в описании метода SQLConnection.loadSchema() .
- Функция SQLITE_VERSION() : Функция sqlite_version() не доступна для использования в инструкциях SQL.
- Функции регулярных выражений (MATCH() и REGEX()) . Эти функции не доступны в инструкциях SQL.
Следующие возможности отличаются в различных реализациях SQLite и Adobe AIR:
- Индексированные параметры инструкций . Во многих реализациях индексированные параметры инструкций основаны на единице. Однако в Adobe AIR индексируемые параметры инструкций основаны на нуле (т.е., первому параметру присваивается индекс 0, второму параметру — индекс 1 и т.д.).
Дополнительные возможности SQL
Следующие типы сходства столбцов по умолчанию не поддерживаются в SQLite, но поддерживаются в Adobe AIR:
Следующие типы литеральных значений по умолчанию не поддерживаются в SQLite, но поддерживаются в Adobe AIR:
- Значение true . Представляет литеральное логическое значение true для работы со столбцами BOOLEAN.
- Значение false . Представляет литеральное логическое значение false для работы со столбцами BOOLEAN.
Поддерживаемые типы данных
В отличие от большинства баз данных SQL, ядро СУБД SQL Adobe AIR не требует, чтобы значения в столбцах таблицы имени определенный тип. Наоборот, среда времени выполнения для управления типами данных использует две концепции: классы хранения и сходство столбцов. В этом разделе описаны классы хранения и сходство столбцов, а также то, как различия типов данных разрешаются в различных условиях:
Классы хранения
Классы хранения представляют типы фактических данных, которые используются для хранения значений в базе данных. Доступны следующие классы хранения.
- NULL . Значение равно NULL .
- INTEGER . Значение является подписанным целым числом.
- REAL . Значение представляет числовое значение с плавающей запятой.
- TEXT . Значение является текстовой строкой (ограничивается 256 МБ).
- BLOB . Значение представляет большой двоичный объект (BLOB); другими словами, необработанные двоичные данные (ограничивается 256 МБ).
Перед выполнением инструкции SQL всем значениям, передаваемым в базу данных в виде литералов, встроенных в инструкцию SQL, или значениям, привязанным при помощи параметров к подготовленной инструкции SQL, назначается класс хранения.
Литералам, являющимся частью инструкции SQL, назначается класс хранения TEXT, если они заключены в одинарные или двойные кавычки, INTEGER, если литерал указан в виде числа без кавычек и без десятичной точки или экспонента, REAL, если литерал представляет собой число без кавычек с десятичной точкой или экспонент, и NULL, если значение равно NULL. Литералы с классом хранения BLOB обозначаются как X"ABCD" . Дополнительные сведения см. в разделе .
Значениям, подставляемым в виде параметров при помощи ассоциативного массива SQLStatement.parameters , назначается класс хранения, которые больше всего напоминает привязку к исходному типу данных. Например, значения int привязываются как класс хранения INTEGER, значениям Number назначается класс хранения REAL, значениям String — класс хранения TEXT, а объектам ByteArray — класс хранения BLOB.
Сходство столбцов
Сходство столбца является рекомендуемым типом для данных в таком столбце. Если в столбце сохраняется значение (посредством инструкции INSERT или UPDATE), среда выполнения пытается преобразовать тип данных этого значение к заданному сходству. Например, если значение Date (экземпляр Date ActionScript или JavaScript) вставляется в столбец со сходством TEXT, значение Date преобразовывается в представление String (эквивалентно вызову метода toString() объекта) перед сохранением в базе данных. Если значение не удается преобразовать к заданному сходству, возникает ошибка и операция не выполняется. При извлечении значения из базы данных при помощи инструкции SELECT , оно возвращается в виде экземпляра класса, соответствующего сходству, независимо от того, было ли оно преобразовано из другого типа в момент сохранения.
Если столбец принимает значения NULL, значение null ActionScript или JavaScript можно использовать как значение параметра для хранения NULL в столбце. При извлечении значения класса хранения NULL в инструкции SELECT оно всегда возвращается как значение null ActionScript или JavaScript независимо от сходства столбца. Если столбец принимает значения NULL, следует всегда проверять значения, извлекаемые из этого столбца, чтобы определить, равны ли они null , прежде чем выполнить попытку приведения значения к ненулевому типу (такому как Number или Boolean).
Каждому столбцу в базе данных назначается одно из следующих сходств типа:
- TEXT (или STRING)
- NUMERIC
- INTEGER
- REAL (или NUMBER)
- BOOLEAN
- XMLLIST
- OBJECT
TEXT (или STRING)
Столбец со сходством TEXT или STRING хранит все данные с использованием классов хранения NULL, TEXT или BLOB. Если в столбец вставляются данные со сходством TEXT, они преобразуются в текстовую форму перед сохранением.
NUMERIC
Столбец со сходством NUMERIC содержит значения с использованием классов хранения NULL, REAL или INTEGER. При вставке текстовых данных в столбец NUMERIC, перед сохранением выполняется попытка их преобразования в целое число или вещественное число. Если преобразование выполняется успешно, значение сохраняется с использованием класса хранения INTEGER или REAL (например, значение "10.05" преобразуется перед сохранением в класс хранения REAL). В случае невозможности выполнения преобразования происходит ошибка. Попытка преобразования значения NULL не выполняется. Значение, извлекаемое из столбца NUMERIC, возвращается как экземпляр самого специфического числового типа, в который подходит значение. Другими словами, если значение является положительным целым числом или 0, оно возвращается как экземпляр uint. Если оно представляет отрицательное целое число, то возвращается как экземпляр int. И, наконец, если в нем присутствует часть после запятой (не целое число), то оно возвращается как экземпляр Number.
INTEGER
По поведению столбец со сходством INTEGER напоминает столбец со сходством NUMERIC, но с одним исключением. Если сохраняемое значение является вещественным значением (таким как экземпляр Number) части после плавающей запятой, или если значение является текстом, которое можно преобразовать в вещественное значение с плавающей запятой, оно преобразуется в целое число и сохраняется с классом хранения INTEGER. При попытке сохранения вещественного значения с частью после плавающей запятой возникает ошибка.
REAL (или NUMBER)
Поведение столбца со сходством REAL или NUMBER аналогично поведению столбца со сходством NUMERIC, однако здесь целочисленные значения принудительно преобразуются в представление с плавающей запятой. Значение в столбце REAL всегда возвращается из базы данных в виде экземпляра Number.
BOOLEAN
Столбец со сходством BOOLEAN хранит истинные (true) или ложные (false) значения. Столбец BOOLEAN принимает значение, являющееся экземпляром Boolean ActionScript или JavaScript. При попытке кода сохранить значение String, String, длина которого превышает ноль, считается "true", а пустое значение String — "false". Если код попытается сохранить числовые данные, то любые ненулевые значения сохраняются как "true", а 0 как "false". При извлечении значения Boolean при помощи инструкции SELECT , оно возвращается как экземпляр Boolean. Не-NULL значения хранятся с использованием класса хранения INTEGER (0 для "false" и 1 для "true") и преобразуются в объекты Boolean во время извлечения данных.
DATE
Столбец со сходством DATE хранит значения даты и времени. Столбец DATE может принимать значения, являющиеся экземплярами Date ActionScript или JavaScript Date. При попытке сохранить значение String в столбец DATE, среда выполнения попытает преобразовать его в юлианскую дату. В случае невозможности выполнения преобразования происходит ошибка. Если код попытается сохранить значение Number, int или uint, то попытка проверки данных не выполняется и значение считается допустимым значением даты по юлианскому календарю. При извлечении значения DATE при помощи инструкции SELECT оно автоматически преобразуется в экземпляр Date. Значения DATE хранятся в виде значений юлианской даты с использованием класса хранения REAL, поэтому операторы сортировки и сравнения работают так, как требуется.
XML или XMLLIST
Столбец со сходством XML или XMLLIST содержит структуры XML. При попытке кода сохранить данные в столбце XML при помощи параметра SQLStatement среда выполнения попытается преобразовать и проверить значение с помощью функции ActionScript XML() или XMLList() . В случае невозможности преобразования значения в допустимый XML происходит ошибка. При попытке сохранения данных с использованием текстового значения SQL литерала (например, INSERT INTO (col1) VALUES (" Invalid XML (no closing tag) ") , разбор значения или проверка не выполняется, поскольку его форма считается правильной. Если сохранить недопустимое значение, то при извлечении оно возвращает пустой объект XML. Значение Data XML и XMLLIST Data сохраняется с использованием класса хранения TEXT или NULL.
OBJECT
Столбец со сходством OBJECT содержит сложные объекты ActionScript или JavaScript, включая экземпляры класса Object, а также экземпляры подклассов Object, такие как экземпляры Array и даже экземпляры пользовательских классов. Сериализация данных столбца OBJECT выполняется в формате AMF3 и они сохраняются с использованием класса хранения BLOB. При извлечении значения выполняется его десериализация из AMF3, и оно возвращается в виде экземпляра класса в том виде, в котором оно было сохранено. Следует отметить, что некоторые классы ActionScript, в особенности объекты представления, можно десериализовать как экземпляры их исходного типа данных. Прежде чем сохранять экземпляр пользовательского класса, необходимо зарегистрировать псевдоним класса при помощи метода flash.net.registerClassAlias() (или в Flex, добавив к объявлению класса метаданные ). Кроме того, перед извлечением таких данных необходимо зарегистрировать такой же псевдоним для класса. Любые данные, правильную десериализацию которых невозможно выполнить по той причине, что класс изначально не поддается десериализации или псевдоним класса отсутствует или несогласован, возвращается как анонимный объект (экземпляр класса Object) со свойствами и значениями, соответствующими изначально сохраненному экземпляру.
NONE
Столбец со сходством NONE не различает классы хранения. Попытка преобразования данных перед вставкой не выполняется.
Определение сходства
Сходство типа столбца определяется по объявленному типу столбца в инструкции CREATE TABLE . При определении типа действуют следующие правила.
- Если тип данных столбца содержит любые строки "CHAR", "CLOB", "STRI" или "TEXT", то столбец имеет сходство TEXT/STRING. Следует отметить, что тип VARCHAR содержит строку "CHAR" и ему назначается сходство TEXT.
- Если тип данных столбца содержит строки "BLOB" или тип данных не задан, то столбец имеет сходство NONE.
- Если тип данных столбца содержит строку "XMLL", то столбец имеет сходство XMLLIST.
- Если типом данных является строка "XML", то столбец имеет сходство XML.
- Если тип данных содержит строку "OBJE", то столбец имеет сходство OBJECT.
- Если тип данных содержит строку "BOOL", то столбец имеет сходство BOOLEAN.
- Если тип данных содержит строку "DATE", то столбец имеет сходство DATE.
- Если тип данных содержит строку "INT" (включая "UINT"), ему назначается сходство INTEGER.
- Если тип данных столбца содержит любые строки "REAL", "NUMB", "FLOA" или "DOUB", то столбец имеет сходство REAL/NUMBER.
- В противном случае, сходством будет NUMERIC.
- Если таблица создана с помощью инструкции CREATE TABLE t AS SELECT... , то тип данных для всех столбов не задается и им назначается сходство NONE.
Типы данных и операторы сравнения
Поддерживаются операторы двоичного сравнения = , < , <= , >= и!= , а также операция проверки заданного членства, оператор IN и оператор троичного сравнения BETWEEN . Подробные сведения об этих операторах см. в разделе .
Результат сравнения зависит от классов хранения двух сравниваемых значений. При сравнении двух значений действуют следующие правила.
- Значение с классом хранения NULL считается меньшим по отношению к любому другому значению (включая другое значение с классом хранения NULL).
- Значение INTEGER или REAL меньше любого значения TEXT или BLOB. При сравнении INTEGER или REAL с другим значением INTEGER или REAL выполняется сравнение чисел.
- Значение TEXT меньше значения BLOB. При сравнении двух значений TEXT выполняется двоичное сравнение.
- При сравнении двух значений BLOB результат всегда определяется по двоичному сравнению.
При выполнении двоичных сравнений классов хранения числа и текста, перед выполнением преобразования база данных пытается преобразовать значения (если требуется). При сравнении классов хранения числа и текста действуют следующие правила (Примечание. Термин выражение , используемый в описанных далее правилах, включает любое скалярное выражение SQL или литерал, отличный от значения столбца. Например, если X и Y.Z представляют имена столбцов, то +X и +Y.Z считаются выражениями):
- При сравнении значения столбца с результатом выражения сходство столбца применяется к результату выражения перед выполнением сравнения.
- Если при сравнении двух значений столбцов один столбец имеет сходство INTEGER, REAL или NUMERIC, а второй нет, то сходство NUMERIC применяется к любым значениям с классом хранения TEXT, извлеченным из не NUMERIC столбца.
- При сравнении результатов двух выражений преобразование не происходит. Результаты сравниваются "как есть". При сравнении строки с числом, последнее всегда меньше строки.
Троичный оператор BETWEEN всегда преобразуется в качестве эквивалента двоичному выражению. Например, a BETWEEN b AND c преобразуется к a >= b AND a <= c , даже если это означает, что разные сходства применяются к a при каждом сравнении, необходимом для вычисления выражения.
Выражения типа a IN (SELECT b ....) следуют трем правилам, перечисленным ранее для двоичного сравнения, то есть, аналогичны a = b . Например, если b — значение столбца, а a — выражение, то сходство b применяется к a перед любым сравнением. Выражение a IN (x, y, z) преобразуется к a = +x OR a = +y OR a = +z . Значения справа от оператора IN (в приведенном примере это значения x , y и z) считаются выражениями, даже если они являются значениями столбца. Если значение слева от оператора IN является столбцом, то используется сходство этого столбца. Если значение является выражением, то преобразование не происходит.
На порядок выполнения сравнений может также влиять предложение COLLATE . Дополнительные сведения см. в разделе .
Типы данных и математические операторы
По каждому из поддерживаемых математических операторов * , / , % , + и - применяется числовое сходство к каждому операнду перед вычислением выражения. Если какой-либо операнд не удается успешно преобразовать в класс хранения NUMERIC, результатом выражения будет NULL .
При использовании оператора сцепления || каждый операнд преобразуется в класс хранения TEXT перед вычислением выражения. Если какой-либо операнд не удается преобразовать в класс хранения NUMERIC, результатом выражения будет NULL . Невозможность преобразования значения может возникать в двух случаях: если значение операнда равно NULL , или есть это объект BLOB с классом хранения, отличным от TEXT.
Типы данных и сортировка
При сортировке значений при помощи предложения ORDER BY , на первое место ставится класс хранения NULL. Затем следуют значения INTEGER и REAL в числовом порядке, далее значения TEXT в двоичном порядке или в зависимости от заданной сортировки (BINARY или NOCASE). Завершают список значения BLOB в двоичном порядке. Перед сортировкой преобразования классов хранения не выполняется.
Типы данных и группировка
При группировке значений с помощью предложение GROUP BY , значения с различными классами хранения считаются разными. Исключением являются значения INTEGER и REAL, которые считаются равными, если их числа эквиваленты. Предложение GROUP BY не приводит к применению сходства к каким-либо значениям.
Типы данных и составные инструкции SELECT
Составные операторы SELECT — UNION , INTERSECT и EXCEPT — выполняют неявное сравнение значений. Перед выполнением этих сравнений к каждому значению может применяться сходство. Такое же сходство (если имеется) применяется ко всем значениям, которые могут быть возвращены в отдельном столбце результирующего набора составной инструкции SELECT . Применяемое сходство является сходством столбца, возвращаемого первым компонентом инструкции SELECT , имеющим значение столбца (а не какой-либо другой тип выражения) в этом положении. Если для заданного столбца составной инструкции SELECT ни один из компонентов инструкции SELECT не возвращает значение столбца, сходство не применяется к значениям из этого столбца перед их сравнением.
Обозначения, используемые в этом документе
В определениях выражений в этом документе использовались следующие обозначения.
- Регистр текста
- ВЕРХНИЙ РЕГИСТР — ключевые слова SQL литерала написаны в верхнем регистре
- нижний регистр — термины местозаполнителей или имена предложений записаны в нижнем регистре
- Символы определений
- ::= — обозначает определение предложения или выражения
- Группировка и альтернативные символы
- | — символ прямой черты используется между альтернативными параметрами и может читаться как "или"
- — элементы в квадратных скобках являются необязательными; в квадратные скобки может быть заключен один элемент или набор альтернативных элементов
- () — круглые скобки, в которых заключены альтернативные варианты (набор элементов, разделенных символами прямой черты) обозначает обязательную группу элементов, то есть, набор элементов, которые являются возможными значениями отдельного обязательного элемента
- Квантификаторы
- + — знак плюса после элемента в круглых скобках означает, что предшествующий ему элемент может встречаться 1 или более раз
- * — символ звездочки после элемента в квадратных скобках означает, что предшествующий ему (заключенный в скобки) элемент может встречаться 0 или более раз
- Символы литерала
- * — символ звездочки в имени столбца или между круглыми скобками после имени функции обозначает символ звездочки, а не квантификатора "0 или более"
- . — символ точки представляет точку литерала
- , — символ запятой представляет запятую литерала
- () — пара круглых скобок, в которые заключено отдельное предложение или элемент обозначает, что скобки являются обязательными символами скобок литерала.
- Другие символы. Если отсутствуют другие обозначения, остальные символы представляют соответствующие символы литерала